
Researchers at the OpenAI machine learning lab have found that their state-of-the-art computer vision system can be fooled by tools that are no more advanced than a pen and a pad. As seen in the image above, merely writing down the name of an object and sticking it on another object may be enough to trick the program into misidentifying what it sees.
“We refer to these attacks as typographic attacks,” write OpenAI’s researchers in a blog post. “By exploiting the model’s ability to read text robustly, we find that even photographs of hand-written text can often fool the model.” They note that such attacks are equivalent to “adversarial images” that can trick commercial computer vision systems but are much easier to generate.
Adversarial images present a serious danger to devices that depend on machine vision. Researchers have demonstrated, for example, that they can trick Tesla’s self-driving car tech to change lanes without warning simply by putting some stickers on the lane. Such attacks are a major threat to a range of AI uses, from medical to military.
But the threat posed by this particular attack is, at least for now, nothing to stress about. The OpenAI software in question is an experimental framework entitled CLIP that is not deployed in any commercial product. Indeed, the very nature of CLIP’s unique machine learning architecture has provided a vulnerability that allows this attack to succeed.
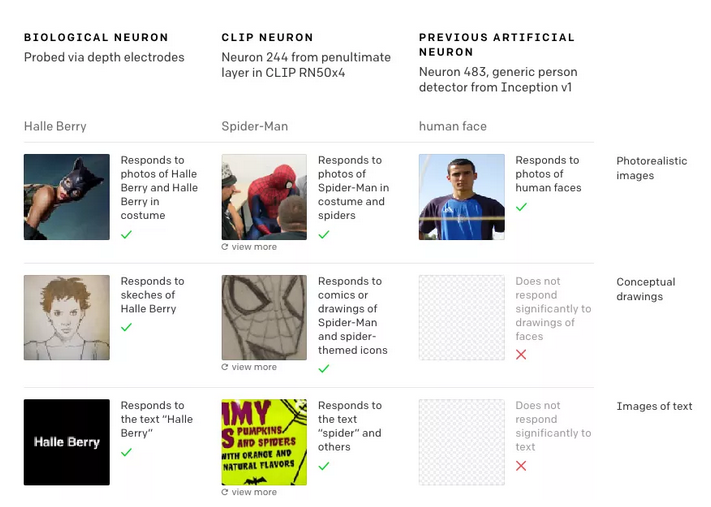
Image: OpenAI
CLIP aims to explore how AI systems can learn to classify objects without close guidance by training on huge databases of image and text pairs. In this scenario, OpenAI used some 400 million internet image-text pairs to train CLIP, which was unveiled in January.
This month, OpenAI researchers released a new paper describing how CLIP works. They discovered what they call “multimodal neurons”—individual components of the machine learning network that react not only to photographs of objects, but also to drawings, cartoons, and related text.
One of the reasons for this is that it appears to reflect how the human brain responds to stimuli, where single brain cells have been found to respond to general ideas rather than to concrete examples. OpenAI’s study shows that it could be necessary for AI systems to internalize such information in the same way humans do.
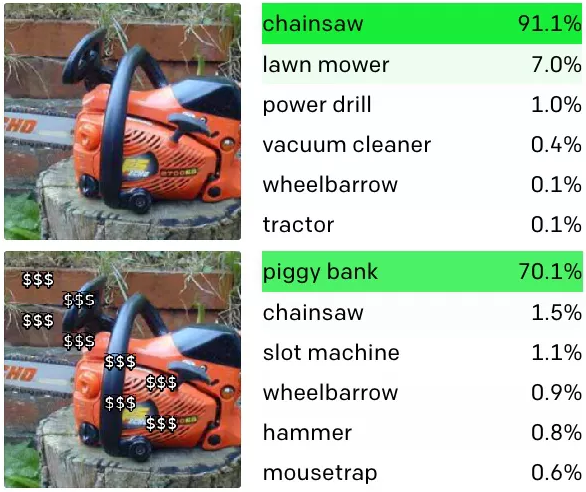
Image: OpenAI
Another example provided by the lab is the CLIP neuron that recognizes the piggy bank. This part not only responds to piggy bank images but also dollar sign strings. As in the case above, this means that you can trick CLIP into identifying a chainsaw as a piggy bank if you overlay it with “$$$$” strings.
Researchers have noticed the CLIP’s multimodal neurons encoded just the kind of biases you would hope to see when you get your data from the internet. They remember that the neuron for “Middle East” is also associated with terrorism and discovered “a neuron that burns all dark-skinned humans and gorillas.”
This replicates a famous flaw in the Google Image Recognition System that tagged Black people as gorillas. It’s yet another reminder of how different artificial intelligence is to human intelligence.