
AI’s holy grail has always been to enable computers to learn the way human beings do. However, today’s most powerful AIs still rely on having certain established rules, such as rules for a game of chess or Go. However, human learning is always messy, learning the principles of life as we go. DeepMind has long tried to build such AIs using games as their setting and test suite. The sister company of Google that focuses on AI research has just unveiled its new achievement in MuZero, an AI that can master a game without previously learning the rules.
The previous AIs of DeepMind such as AlphaGo has been widely covered in the media to defeat human champions in their respective games. Impressive as they might have been, the ultimate goal was only a few steps short of them. In particular, AlphaGo had the benefit of not only knowing Go’s rules but also domain knowledge and data from human players. AlphaGo Zero and AlphaZero, their predecessors, could still depend on getting the rule book to learn from.
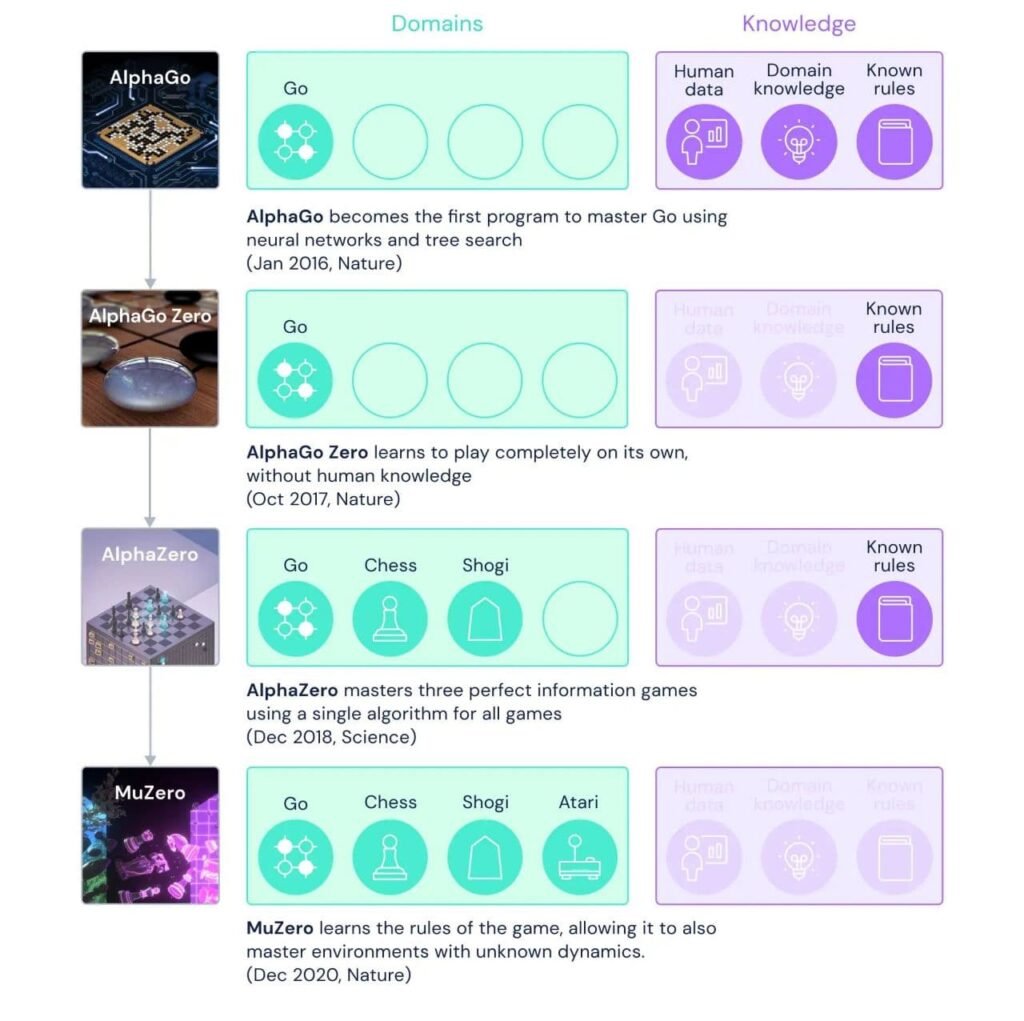
While these AIs excelled in games with complex strategies but simple graphics, when applied to more visually complex games where the rules are not so simple to infer, they failed. This is where the new MuZero AI comes in, and to test their theory, it uses a range of Atari games, including Ms. Pac-Man.
In order to solve the learning issue, most AI researchers use two methods, one of which is the lookahead search that relies on the rules or knowledge of a game. Model-based planning does learn by creating an accurate model of an environment but at the expense of being overly complex. The benefit of MuZero is that it models only the important parts of the environment, such as understanding that an umbrella can help to keep you dry under the rain instead of modelling the movement of all raindrops.

The efficiency and pace that MuZero was able to master games certainly impressed DeepMind, even though only a small number of steps were taken to plan ahead. It hopes this new AI learning approach can be extended to messy real-world situations in which the rules are not well-defined.
2 Comments
Pingback: Should We Fear AI? - Craffic
Pingback: FlavorGraph by Sony uses AI to pair ingredients with each other - Craffic